Misfit_data_set

Contents
Data Structure: Misfit_data_set |
|
Description |
Data defining the Misfit Evaluation |
Usage |
Misfit_data_set NUM=ival where ival is the data structure number |
Description |
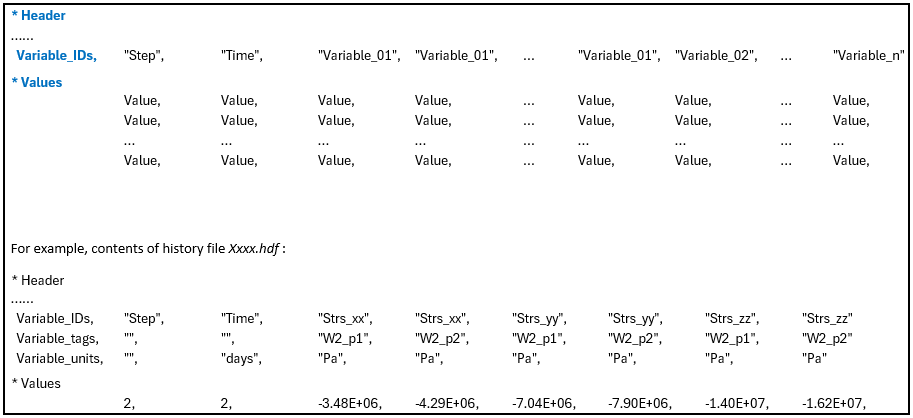
Overview The Misfit_data_set data structure defines the history result files containing the experimental (also referred to as target) and model solutions, together with the variable and weighting data to be used in computing the misfit between the target data and model results.
The minimum data requirement is the name of the target data file and the assoicated model (history) set number. In this case the misfit is computed using a normalised root mean square error for all common variables. Alternatively, specific variables may be identified for comparison and computation of misfit. In addition, individual variables or specific time intervals may be assigned weighting. This allows the misfit evaluation to be focused on the results of a particular section in a history file (e.g. for a particular time range).
Both the target data and model results are defined in standard ParaGeo format as columns of data associated with individual variables in comma separated value (csv) format. The target data should contain as a minimum a Header section with the variable IDs and a section with the values for each variable, i.e.
Notes •Several Misfit_data_set data structures may be defined, one for each target to be used in the inverse procedure. This is required if either the experimental data or the model results are contained in different files.
|
| Experiment_filename File containing target results |
Usage |
||||
|
||||
Description |
||||
The Experiment_filename definition is compulsory and it defines the name of the history file that contains the target results. This target history file should be located in the target directory defined within File_data data structure.
|
| Experiment_set_id Name of the data set for the experiment |
Usage |
||||
|
||||
Description |
||||
Name of the data set for the experiment.
|
| Model_set_id Name of the data set for the model |
Usage |
||||
|
||||
Description |
||||
Name of the data set for the model.
|
| Model_set_number History set ID number for model results |
Usage |
||||
|
||||
Description |
||||
The Model_set_number definition is compulsory and it defines the ID number of the history data set in the template data file. This template data file is located in the template directory which is defined within the File_data data structure. The model simulations will generate history file results with this ID number and these model results will be used for comparing with the target results which is defined by Experiment_filename.
|
| Error_type Type of function for computing misfit |
Usage |
||||
|
||||
Description |
||||
Error_type defines the method of computing the misfit between the target (or experimental) and model results. Valid misfit types are: •"RMS" or "Root_mean_square" - Root mean square of the differences normalised by the root mean square of the target values. •"NormAve" or "Normalised_average" - Average of the absolute differences normalised by the corresponding individual target values.
|
| Experiment_variable_ids List of target variables to be used in the Misfit evaluation |
Usage |
|||||||||||||||
|
|||||||||||||||
Description |
|||||||||||||||
Experiment_variable_ids defines a list of variables in the target (or experimental) history file that should be used in the misfit calculation; i.e. it allows exclusion of variables that are present but should not be taken into account or are not important.
Notes •By default the experimental and model history variable names are considered identical. •If the variable names in the experimental and model history files differ then the list of equivalent names in the model history file is defined using Model_variable_ids. •If Experiment_variable_ids is not defined then all common variables in the target and model history file will be used in the misfit evaluation.
|
|||||||||||||||
| Experiment_variable_tags List of tags for the target variables |
Usage |
|||||||||||||||
|
|||||||||||||||
Description |
|||||||||||||||
Defines a list of tags for each of the target variables listed in Experiment_variable_ids. Definition of Experimental_variable_tags is optional, however, it can be used to identify a particular column of data when the primary variable ID occurs more than once in the experimental data set; e.g. for axial strain values at multiple locations, the location could be identified using a different name tag.
|
|||||||||||||||
| Model_variable_ids List of model variables to be used in the Misfit evaluation |
Usage |
|||||||||||||||
|
|||||||||||||||
Description |
|||||||||||||||
Model_variable_ids defines a list of variable names in the model history file to be used in the misfit evaluation. If the target variable names defined in Experimental_variable_ids are identical, then Model_variable_ids need not be defined.
|
|||||||||||||||
| Model_variable_tags List of tags for the model variables |
Usage |
|||||||||||||||
|
|||||||||||||||
Description |
|||||||||||||||
Defines a list of tags for each of the model variables listed in Model_variable_ids. Definition of Model_variable_tags is optional, however, it can be used to identify a particular column of data when the primary variable ID is defined for multiple locations in the model history set; e.g. for axial strain values at multiple locations, the location could be identified using a different name tag.
|
|||||||||||||||
| Variable_weights List of weights for combining the misfit of multiple variables |
Usage |
|||||||||||||||
|
|||||||||||||||
Description |
|||||||||||||||
Variable_weights defines a list of weights to be assigned to individual variables in a multiple misfit variable scenario. These weights are then used when evaluating the total misfit which is defined as the weighted average of the misfit of individual variables. If Variable_weights is not defined, all variables are assigned unit weighting.
Notes •Experiment_variable_ids must be defined if Variable_weights is defined.
|
|||||||||||||||
| Time_points List of times for evaluation of misfit |
Usage |
|||||||||||||||
|
|||||||||||||||
Description |
|||||||||||||||
Time_points specifies a list of times or an individual time where the misfit should be evaluated. If Time_points is not defined the misfit is evaluated at all target times. If the model solution time does not cover the complete time range in the target results then the misfit is evaluated using the common time range.
|
|||||||||||||||
| Time_point_weights List of weights for individual time points |
Usage |
|||||||||||||||
|
|||||||||||||||
Description |
|||||||||||||||
Time_point_weights defines a list of weights to be assigned to individual comparison times. These weights are then used when evaluating the misfit for each variable (using the method defined using Error_type). If Time_point_weights is not defined the misfit at each time point is assigned unit weighting. Time_point_weights applies to all variables in the misfit evaluation.
Notes •Time_points must be defined if Time_point_weights is defined and the number of time point weights and time points must be identical. •The weights are defined relative to the default weight of 1.0; i.e. to increase the weighting at a specific time, define weight > 1.0. Conversely to decrease the weighting at a specific time, define weight < 1.0.
|
|||||||||||||||
| Time_curve_weights List of time range and corresponding weights |
Usage |
|||||||||||||||
|
|||||||||||||||
Description |
|||||||||||||||
Time_curve_weights defines a list of time range and corresponding weights via a start time, end time and weight. Several time ranges may be specified. If the time ranges overlap then the largest weighting in the overlap zone will be used. Time_curve_weights applies to all variables in the misfit evaluation. The specific data for each time curve weight is: •Location 1 - Start time for range •Location 2 - End time for range •Location 3 - Weight
Notes •The weights are defined relative to the default weight of 1.0; i.e. to increase the weighting within a time range, define weight > 1.0. Conversely to decrease the weighting within a time range, define weight < 1.0. •To exclude the results for misfit evaluation within a time range, for example, at initial times, define weight = 0.
|
|||||||||||||||
| Set_weight Weight for the current misfit data set |
Usage |
||||
|
||||
Description |
||||
Defines the weight assigned to the current misfit data set.
|